

Research
Researcher: Dr. Assaf Zaritsky
(computational cell dynamics, data science in cell imaging)
Student: Katya Smoliansky
Using Microscopy and Generative Networks to Infer Novel Molecular Interactions PI: Assaf Zaritsky (computational cell dynamics, data science in cell imaging) Department of Software and Information Systems Engineering, Ben-Gurion University of the Negev, Beer Sheva 84105, Israel.
Email: assafzar@gmail.com. Phone: 972-50-753-8585.
Lab website
Cells are the fundamental unit of structure and function of all organisms. Proteins are the molecular machines that define the cell architecture, organization, and function. Microscopy is the only technology that allows us to see live cell behavior and to correlate cell function to protein quantity and location. Recent studies have demonstrated that label-free (without fluorescent stains for specific molecules) images contain information on the molecular organization within the cell by using machine learning-based generative approaches.
The potential generation of such “virtual integrated cells” may overcome inherent limitations in optics and molecular biology that limits the number of proteins that can be concurrently images in a live cell. We propose to make the next big step by using matched fluorescent and label free images to predict (asymmetric) protein-protein interactions that will be used to identify novel molecular pathways that can be then verified experimentally. Interactions among different proteins is poorly characterized due to the difficulty in live imaging multiple different proteins in a cell.
We propose here a proof-of-concept of a methodology that will enable predictive modeling of cell states and behavior, based on virtual predicted molecular organization and interactions from label free images. Such system-level understanding of molecular interactions will be a huge advance towards the “holy grail” of cell biology - an understanding of the cell as an integrated complex system.
Students taking part in this project: Katya Smoliansky, M.Sc. student, Department of Computer Science. Gil Baron, M.Sc. student, Department of Software and Information Systems Engineering.  Summary
Summary

Researchers: Prof. Aryeh Kontorovich, Computer Science -- statistical learning, big data and Dr. Rami Puzis, Software and Information Systems Engineering -- network analysis, cyber security
Students: דורון כהן, טטיאנה פרנקלך
Smartphones are an essential part of our everyday life, providing a means of communication, information, self-care services, entertainment, and more. Yet, Android app markets are filled with numerous malicious applications that threaten mobile users' security and privacy. Due to the ever-increasing number of both malicious and benign applications, there is a need for scalable malware detectors that can efficiently address big data challenges. Motivated by large-scale recommender systems, we propose a static application analysis method that differentiates malicious and benign applications based on an app similarity graph (ASG) and classification based on nearest neighbors. In order to address the big-data challenges, we perform sample compression where a small number of significant anchor APKs are selected in order to represent the complete dataset.
We demonstrate our method on the Drebin benchmark in both balanced and unbalanced settings and on a dataset of approximately 190k applications provided by VirusTotal, achieving an accuracy of 0.975 in balanced settings.
Researcher: Dr. Achiya Elyasaf, Collaborator: Mr. Amit Livne
user context to provide personalized services. The contextual information can be driven from sensors in order to improve the accuracy of the recommendations. Yet, generating accurate recommendations is not enough to constitute a useful system from the users' perspective, since certain contextual information may cause different issues, such as draining the user's battery, privacy issues, and more. Additionally, adding high-dimensional contextual information may increase both the dimensionality and sparsity of the model.
Previous studies suggest reducing the amount of contextual information by selecting the most suitable contextual information using domain knowledge. While in most studies the set of contexts is both small enough to handle and sufficient to prevent sparsity, such context sets do not necessarily represent an optimal set of features for the recommendation process. Another solution is compressing it into a denser latent space, thus disrupting the ability to explain the recommendation item to the user, and damaging users' trust.
The main goal of this proposal is to develop new methodologies for creating CARS models, that will allow for controlling user aspects, such as privacy and battery consumption. Specifically, we propose to develop a feature-selection algorithm, based on evolutionary algorithms (EA), for explicitly incorporating contextual information within CARS (see Figure 1). In a preliminary experiment with a small CARS dataset derived from mobile phones, EA produced different subsets of contextual features that demonstrated similar high-accuracy values and interoperability of the provided recommendations. Thus, we were able to manually examine the effect of the selected features on both accuracy and user aspects (i.e., privacy and battery optimization).
We believe that our approach will contribute to the emerging field of explainable dynamic CARS, and yield a novel type of explanations. Moreover, this approach can be later extended to general recommender systems and contribute to the larger community.
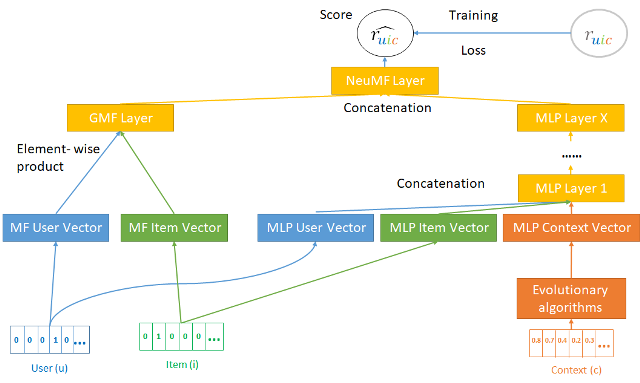
Figure 1. The proposed framework. An evolutionary algorithm evolves subsets of the contextual information (features), that are explicitly incorporated within a context-aware recommender system.
Researcher: Dr. Yaron Orenstein, bioinformatics
Student: Mira Barshai
Detecting unique molecular structures in the Corona virus genome
The corona virus genome contains almost 30,000 nucleotides. This genome is not just a long string over A, C, G and U, but rather a structured molecule. The structure of the molecule, on top of its nucleotide content, can shed light on the function of different regions in the genome. Unfortunately, measuring the structure of the genome is a long, complex and time-consuming process. Instead, researchers often rely on measurements made on other genomes, train a model to predict them, and then apply them to novel genomes, such as the Corona virus genome.
In this project, we are looking for unique structures, called RNA G-quadruplexes, in the Corona virus genome. We plan to train a deep neural network to predict such structures based on a given RNA sequence. The network will be trained on available high-throughput data collected throughout the human transcriptome, providing millions of data points. Once we develop an accurate predictor, we will use it to predict RNA G-quadruplex structures in the Corona virus genome, and experimentally verify the top candidates. Verified structures may serve as potential therapeutic drug targets.